Transfer learning with PyTorch and Huggingface Transformers
One of the most powerful arguments for incorporating deep learning models into your workflow is the possibility of transfer learning: using a pre-trained model’s latent representations as a starting point for your own modeling task. This can be particularly useful when you have a fairly small number of labeled examples, but the task in question is similar to a pre-existing model’s task. So how easy is it to do transfer learning with an LLM? As we’ll see, with HuggingFace’s transformers library, it’s actually quite easy.
A toy problem
Before diving into the code, let’s develop a motivating problem. Suppose we have a corpus of text, and suppose further that we have some set of labels we want to assign to each word in the text. Common examples of this type of natural language processing problem include things like:
- Part-of-speech tagging: What part of speech (noun, verb, adjective, …) is a given word?
- Named entity recognition: Is the given word or phrase a named entity (a person, place, country, …)?
- Information extraction: Find specific types of data in a document (what was the sales tax on this receipt? etc)
These are all examples of token-level classification tasks. For our toy problem, we’ll consider an even simpler one: what letter does a word begin with? This classification task is obviously contrived, but it has one key feature: labels can be easily computed from any body of text. For training data, I’ll be using Moby-Dick, which is available in plaintext from Project Gutenberg.
What is transfer learning, and why use it?
We could easily attack the token tagging exercise described above with an arbitrary NLP model built “from scratch.” However, transfer learning allows us to leverage models (such as LLMs) which have been pre-trained on large text datasets, reducing the need for labeled data and potentially leading to both faster training and more accurate predictions. In transfer learning, the idea is to start from a pre-trained model’s latent representation of the input and apply a smaller (often single-layer) net downstream to solve the specific classification or regression task.
An intuition for why this often works in NLP is that large language models are trained for what is essentially the most difficult token-level task: inferring masked tokens from their surrounding context. If you can construct a latent vector that lets you accurately guess exactly what the missing word is, that same latent vector probably contains all the information needed to determine, for instance, what part of speech that token is.
This should also give a flavor for what types of problems transfer learning will not help with: if your task is sufficiently different from the pretrained model’s task, the latent representation learned by the pretrained model may not be useful for your task.
Note that transfer learning imposes a few limitations on your problem domain as well. The most important one is that the pretrained model must be fed inputs of the same shape and structure that it was trained on. For instance, if your LLM was only trained on plaintext, but you also have additional features (say, font sizes) for each token, the pretrained model will not be able to ingest those additional features.
Transfer learning in PyTorch with HuggingFace Transformers
Now let’s get to the meat of the post: leveraging the HuggingFace Transformers library to do transfer learning in PyTorch.
Data engineering
First, let’s construct our training data and labels. For the corpus, I’ve just taken each line from Moby-Dick:
with open("moby-dick.txt", "r") as f:
corpus = f.read().split("\n")
To create the labels, we now have a dependency on the choice of pretrained model.
The reason is that we need labels per token, and what constitutes a token will differ depending on the pretrained model’s expected tokenizer.
To keep things a reasonable size, I’ll use bert-base-uncased.
Create an instance of the tokenizer:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(
"bert-base-uncased",
clean_up_tokenization_spaces=False
)
To see how a sentence can get tokenized, just use the .tokenize method:
tokenizer.tokenize("Hello, world!")
# ['hello', ',', 'world', '!']
When a word is not part of the vocabulary, BERT’s tokenizer will split it up:
tokenizer.tokenize("amridodgifier")
# ['am', '##rid', '##od', '##gi', '##fi', '##er']
This is why it is necessary to generate labels on the tokenized text. Recall that, in this problem, we wanted to predict the first letter of each word. Here’s a function to predict that letter and encode it as a digit between 1 and 26 (case-insensitive), with 0 used for non-word characters:
letters = "abcdefghijklmnopqrstuv"
label_lookup = {x: i + 1 for i, x in enumerate(letters)}
def label_sentence(sentence):
tokens = tokenizer.tokenize(sentence)
# include labels for [CLS] and [SEP] tokens
return torch.tensor(
[0] + [label_lookup.get(x[0], 0) for x in tokens] + [0]
).long()
The BERT tokenizer will insert special tokens [CLS] and [SEP] at the beginning and ending of each line, which should also be labeled as 0 (not a letter) for our problem.
The labeled corpus is then just:
labels = [label_sentence(x) for x in corpus]
Model setup
Now let’s define a PyTorch model that can incorporate a pretrained Huggingface transformer.
import torch
import torch.nn as nn
class TransferLearner(nn.Module):
def __init__(self, pretrained_model, classifier):
super().__init__()
self.pretrained_model = pretrained_model
self.classifier = classifier
def forward(self, input_ids, attention_mask=None):
# 1. get the latent representations from
# the pretrained model.
outputs = self.pretrained_model(
input_ids=input_ids,
attention_mask=attention_mask
)
# `outputs` is a ModelOutput tuple;
# 0 is the token-level latents
# and 1 the sentence-level latents.
# shape (batch_size, seq_len, hidden_size)
sequence_output = outputs[0]
# 2. Pass the latent representations
# through the classifier to get the
# logits.
# shape (batch_size, seq_len, num_labels)
logits = self.classifier(sequence_output)
return logits
So far this looks like a pretty standard composite model in PyTorch.
(And that’s a good thing! A goal of Huggingface Transformers is to make transformers easy to work with, and as such they can be dropped straight in to behave like any other nn.Module instance.)
To set this up using BERT for our 26 + 1 letter classification task, let’s create pretrained_model and classifier models:
from transformers import AutoModel
pretrained_model = AutoModel.from_pretrained("bert-base-uncased")
classifier = nn.Linear(pretrained_model.config.hidden_size, 27)
Training loop
Now let’s create an instance of our TransferLearner:
transfer_learner = TransferLearner(pretrained_model, classifier)
In transfer learning, it’s common to freeze the weights of the pretrained model (i.e., only train the classifier, don’t update BERT’s weights).
This can improve training times (as fewer weights need to be updated), and preserves (for better or worse) the original latent representations of the pretrained model.
Here’s how to do this:
for param in transfer_learner.pretrained_model.parameters():
param.requires_grad = False
The training loop is very standard:
import torch.optim as optim
from torch.nn.utils.rnn import pad_sequence
import random
BATCH_SIZE = 128
EPOCHS = 100
optimizer = optim.Adam(transfer_learner.parameters(), lr=0.001)
loss_fn = nn.CrossEntropyLoss()
data = list(zip(encoded_corpus, labels))
for epoch in range(EPOCHS):
optimizer.zero_grad()
# X and y are lists of tensors
X, y = zip(*random.choices(data, k=BATCH_SIZE))
# padding joins the lists into a single tensor
# of shape (BATCH_SIZE, max(sentence_len))
# by inserting padding tokens
padded_X = pad_sequence(X, batch_first=True, padding_value=0)
attn_mask = (padded_X != 0)
padded_y = pad_sequence(y, batch_first=True, padding_value=0)
pred_y = transfer_learner(padded_X, attention_mask=attn_mask)
# when computing the loss, we need to omit
# the padding tokens from the computation
loss = loss_fn(pred_y[attn_mask], padded_y[attn_mask])
loss.backward()
optimizer.step()
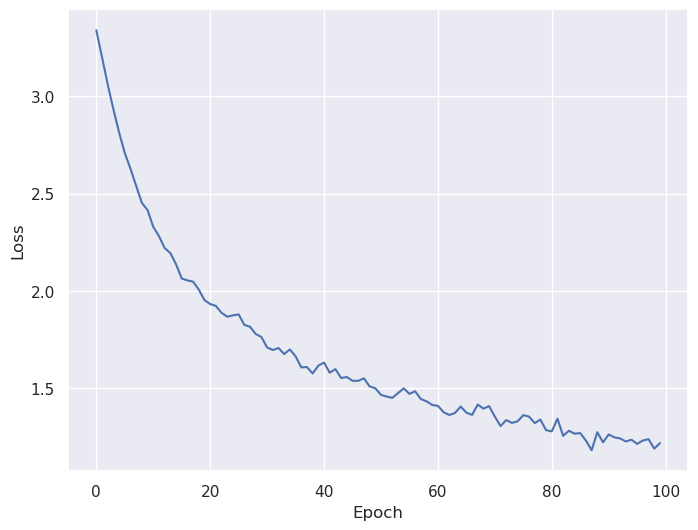
We see good convergence during training:
Predictions
Finally, let’s generate some predictions with this model. Here’s a convenience function that bundles up the tokenization/encoding, prediction, and decoding steps:
def predict(txt: str) -> list[str]:
input_ids = tokenizer.encode(txt, return_tensors='pt')
with torch.no_grad():
preds = torch.softmax(
transfer_learner(input_ids),
dim=-1
)[0].argmax(dim=-1)
return [letters[i - 1] if i != 0 else '' for i in preds]
And a few examples to close things out.
The first one is promising:
predict("This is a test!")
# returns ['', 't', 'i', 'a', 't', '', '']
The second, not so much!
predict("The quick brown fox jumped over the lazy dog")
# returns ['', 't', '', '', '', '', 'o', 't', '', '', '']
These results are not entirely surprising: the is probably the most common word in the English language, so there are likely many examples in the training set.
On the other hand, lazy appears only twice in the entire text of Moby-Dick—it is quite plausible that it did not show up in our training loop at all!
And the great shroud of the sea rolled on as it rolled five thousand years ago.