Lobotomizing GPT
Modern LLMs are impressive pieces of machinery, capable of feats across many domains that were previously thought to be unique signifiers of human intelligence. This power and generality comes from their incredible size, which allows LLMs to compress huge quantities of information and recognize highly sophisticated patterns.
But it’s all a bit much, isn’t it?
Haven’t you ever wanted to just have a little tiny model that fits on a Raspberry Pi, and is also, well, kind of stupid? Have you ever needed a model to do just one thing, only one thing, and nothing else—but you couldn’t be bothered to dust off Scikit-Learn and build one from scratch?
In this blog post I’ll provide a guide on how to do exactly that. We’ll take a large-ish model (in this case, GPT-2), distill it down to a much smaller model, and simultaneously constrain its output so that it can only perform a single, highly contrived task. Despite the somewhat tongue-in-cheek introduction, the approach described here is actually broadly useful for many practical applications: you often don’t want your LLM to spit out arbitrary text, and frequently you have turned to an LLM to solve a single specific task (and therefore do not need its capabilities outside of that narrow domain).
Prerequisites
If you want to follow along with the code in this post, you’ll need the following packages:
- PyTorch (
torch) (of course) - HuggingFace
transformers - HuggingFace
datasets - A CoNLL-U parser, like
conllu - The
outlinespackage
As a dataset, I’ll be using the UD-English-GUM corpus (see below).
Problem statement
The toy problem I’m going to use is part-of-speech tagging. Classically, this is a token classification problem. Instead, we want to treat it as a text generation problem. For a given input sentence, we want our LLM to produce a JSON object identifying the tags of each word in the input.
Example
Input: Get your feet off of there.
Output: {
"tokens":[
{"text":"Get","pos":"VERB"},
{"text":"your","pos":"PRON"},
{"text":"feet","pos":"NOUN"},
{"text":"off","pos":"ADP"},
{"text":"of","pos":"ADP"},
{"text":"there","pos":"ADV"},
{"text":".","pos":"PUNCT"}
]
}
In particular, we want to constrain the output of our LLM to adhere to the following data structure (implemented using pydantic):
import pydantic
class Token(pydantic.BaseModel):
text: str
pos: str
class AnnotatedSentence(pydantic.BaseModel):
tokens: list[Token]
In order to generate a training set, I’ve pulled down the CoNNL-U files mentioned above. CoNNL-U files consist of richly annotated natural language—in addition to part-of-speech tags, they include dependency relations and other linguistic properties. We will completely ignore these. For our purposes, the resulting training dataset can be obtained in the following way:
import cnnlu
def sent_to_annots(sentence):
return AnnotatedSentence(
tokens=[Token(text=token["form"], pos=token["upostag"])
for token in sentences]
)
The plaintext of a sentence can be obtained via
" ".join([tok["form"] for tok in sentence])
There are two main practical issues that crop up when trying to use a generative LLM for this task:
-
The model may not produce valid outputs: it may not even produce valid JSON, let alone JSON that adheres to our schema. To address this, we’ll apply constrained decoding.
-
A pretrained model is likely larger than we need: we only want to apply this model to a very narrow task, so we may not need an 8bn or 70bn parameter model. To create a smaller version of the parent model while (hopefully) preserving the capabilities relevant to our task, we’ll use model distillation.
Let’s take each of these in turn.
Constrained decoding
Constrained decoding is method for controlling the outputs of a generative model. Recall that LLMs are a type of statistical language model. The output of a model such as GPT is the predicted probabilities for each possible next token, given an input token sequence (a “context”). More precisely, to help ensure numerical stability during training, these models typically predict logits.
One way to constrain the output is by directly modifying these logits (by setting the logits of any invalid token to -inf.)
For example, suppose we wanted to force the output of our model to adhere to the following schema:
class CarInfo(pydantic.BaseModel):
make: CarEnum
model: str
year: int
mpg: float
Token generation can be treated as a finite state machine, and at each step any illegal state transitions (i.e. those that would result in a string not adhering to our schema) can be disallowed. An example of this process is depicted below:
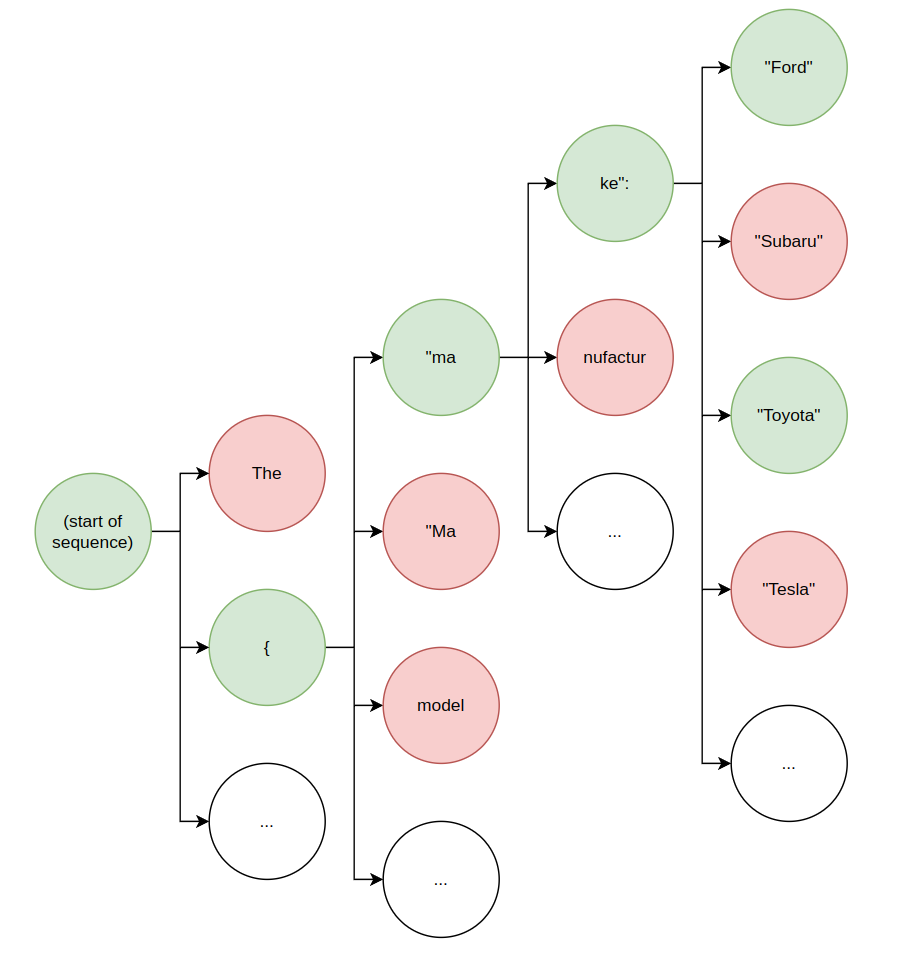
Valid next states are colored green, and invalid next states are colored in red.
The HuggingFace transformers library provides a LogitsProcessor abstraction which is used as part of a generation pipeline to apply post-processing to the logits predicted by a given model:
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
output = pipe(
'The quick brown fox',
logits_processor=LogitsProcessorList([logits_processor])
)
This allows us to impose any arbitrary logits postprocessing we want on the model’s outputs prior to selecting the next token.
The tricky part, then, is to impose constraints based on a given schema.
Luckily, outlines by .TXT is a package that compiles a given schema (as described by a [pydantic class]) to a LogitsProcessor powered by a finite state machine.
Here’s how to use it:
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
LogitsProcessorList,
pipeline
)
from outlines.processors import JSONLogitsProcessor
from outlines.models.transformers import TransformerTokenizer
model = AutoModelForCausalLM.from_pretrained("openai-community/gpt2")
tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2")
logits_processor = JSONLogitsProcessor(
AnnotatedSentence, # the name of our pydantic class
tokenizer=TransformerTokenizer(tokenizer), # outlines wrapper
)
pipe = pipeline("text-generation",
model=model,
tokenizer=tokenizer,
logits_processor=LogitsProcessorList([logits_processor])
)
pipe("The quick brown fox")[0]["generated_text"]
# returns, for instance
# 'The quick brown fox{"tokens":[{"text": "You might'
If all you want to do is produce structured outputs according to a particular schema constraint, then you can stop here. For our purposes, however, we want to also access the logits directly for use during training.
This is a bit more complicated, and requires an apparently undocumented implementation detail of the JSONLogitsProcessor from outlines which took me an embarassing amount of time to uncover.
The secret is this: the state machine powering JSONLogitsProcessor expects to receive an eos_token as the first token in the sequence.
So, for instance, to generate completions according to our schema, we should do the following:
input_str = '<|endoftext|>{"tokens":[{"'
inputs = tokenizer(input_str, return_tensors='pt')
model_logits = model(**inputs).logits
out_logits = None
# step through each token in the input
# - this is important to update the processor state!
for i in range(inputs.input_ids.shape[1]):
out_logits = logits_processor(
inputs.input_ids[:,:i+1],
model_logits[:,i,:]
)
# do something with the logits,
# e.g. see what the most likely tokens are
topk = out_logits.topk(5).indices.reshape(-1)
tokenizer.convert_ids_to_tokens(topk)
# returns ['text', 't', 'tex', 'te', '$']
We will come back to these logits shortly. But first, let’s take a look at model distillation.
Model distillation
Model distillation is a technique for constructing smaller versions of models by training the smaller “student” model on the predictions of the larger “teacher” model. In particular, typically the student model is trained on the logits predicted by the teacher model (rather than, say, just shrinking embedding dimensions and refitting on the same corpus as the original model). In some cases, the training corpus used to generate the teacher’s logits is a subset of, or entirely different from, the corpus originally used to train the teacher model. (For example, you might do this if the student is intended to be used only in a specialized domain.)
Let’s start by just distilling GPT-2 to a smaller version, on our CoNLL-U dataset. Start by loading in some necessary libraries:
import torch
import torch.nn as nn
from transformers import (
GPT2Config,
GPT2LMHeadModel,
AutoTokenizer,
Trainer,
TrainingArguments,
DataCollatorForLanguageModeling
)
from datasets import Dataset
I’ve constructed an example dataset by concatenating the sentence text and the JSON-format text together. Each example is a string, for instance:
How to Tell a Joke<|endoftext|>{"tokens":[{"text":"How","pos":"ADV"},
{"text":"to","pos":"PART"},{"text":"Tell","pos":"VERB"},{"text":"a",
"pos":"DET"},{"text":"Joke","pos":"NOUN"}]}
We’ll use the Huggingface datasets package for management of this training set.
Let’s construct our Dataset object, and then tokenize each element:
# examples is a list[str] as above
data = Dataset.from_dict({"text": examples})
def preprocess(data):
inputs = tokenizer(data["text"], max_length=512, truncation=True)
return inputs
# get a list of input ids and attention mask
tokenized_data = data.map(
preprocess, batched=True, remove_columns="text")
Next, let’s set up our miniature GPT. GPT-2 has 768-dimensional embeddings, we’ll trim things down to just 192 dimensions:
cfg = GPT2Config(
n_embd=192,
n_layer=12,
n_head=12,
)
student = GPT2LMHeadModel(cfg)
This student model is only 12% the size of GPT-2: it has about 15m parameters, as compared to GPT-2’s 124m.
By default, GPT-2 doesn’t use padding tokens; we’ll need to add those for training. For padding, we need to add a pad token:
tokenizer.add_special_tokens({"pad_token": '<|pad|>'})
student.resize_token_embeddings(len(tokenizer))
student.pad_token_id = tokenizer.pad_token_id
teacher.resize_token_embeddings(len(tokenizer))
teacher.pad_token_id = tokenizer.pad_token_id
Next, we need to set up the loss function. Since we are trying to train the student model to match the teacher model’s logits (a probability distribution), Kullback-Leibler divergence is an appropriate choice of loss criterion.
Here’s a loss function:
# Distillation loss: Logit matching
def compute_loss(teacher_outputs, student_outputs):
# Use KL-divergence between teacher and student logits
teacher_logits = teacher_outputs.logits
student_logits = student_outputs.logits
loss_fn = nn.KLDivLoss(reduction="batchmean")
return loss_fn(
student_logits.log_softmax(dim=-1),
teacher_logits.softmax(dim=-1)
)
To use this custom loss with a Huggingface Trainer, we need to subclass the Trainer class:
class DistillationTrainer(Trainer):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
def compute_loss(
self,
model,
inputs,
return_outputs=False,
num_items_in_batch = None):
inputs = {k: v.to(self.args.device)
for k, v in inputs.items()}
with torch.no_grad():
teacher_outputs = teacher(**inputs)
student_outputs = model(**inputs)
loss = compute_loss(teacher_outputs, student_outputs)
return (loss, student_outputs) if return_outputs else loss
The final step before we train our distilled GPT is to pick training arguments and a data collator:
training_args = TrainingArguments(
output_dir="./distilled-model",
learning_rate=5e-5,
per_device_train_batch_size=8,
num_train_epochs=25,
logging_dir="./logs",
save_steps=1000,
save_total_limit=2,
bf16=True # mixed precision for faster training
)
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False
)
trainer = DistillationTrainer(
model=student,
args=training_args,
train_dataset=tokenized_dataset,
data_collator=data_collator,
)
Once this is all done, we can generate some text with our distilled model:
from transformers import pipeline
student_generator = pipeline(
"text-generation",
tokenizer=tokenizer,
model=student,
device=device
)
student_generator(
'It was the best of times<|endoftext|>{"tokens":[',
max_length=15,
truncation=True,
num_return_sequences=5,
do_sample=True,
temperature=1
)
# returns
# 'It was the best of times<|endoftext|>{"tokens":[hreftext":"'
# 'It was the best of times<|endoftext|>{"tokens":[typecodes'
# 'It was the best of times<|endoftext|>{"tokens":[name-type'
# 'It was the best of times<|endoftext|>{"tokens":[","title\n'
# 'It was the best of times<|endoftext|>{"tokens":[idcategory,'
It’s easy to see that our distilled model has not learned our schema. But why would it? The distillation process above has taught the student model to approximate GPT-2’s predicted probabilities for those tokens, not fine-tuned the model on those sample sentences.
Distilled and constrained generation
To get the model to follow our schema, we may try to teach it the correct schema using the JSONLogitsProcessor we built above.
However, there are some practical obstacles to this: first (and somewhat unfortunately), the HuggingFace datasets library doesn’t seem to play nicely with LogitsProcessor.
I suspect the specific issue is that, because datasets uses Arrow under the hood, it struggles to handle the logits tensor outputs from the processor.
So, in order to incorporate token masks (which is how I will model the constraints), you will need to write an old-fashioned training loop, rather than relying on datasets and the Trainer class.
The second and greater impediment (at least from the perspective of writing this blog) is that the JSONLogitsProcessor is not easily vectorized, so it must be applied sequentially, one example at a time.
This becomes burdensome when applied to a dataset of any significant size.
Nevertheless, before proposing an alternative approach, I will sketch out how one could incorporate constraints into model distillation.
Recall that the training inputs to our model are strings of the form
The dog ran.<|endoftext|>{"tokens": [{"text": "The", "pos": "DA", ...
What we would like to do is, for each token in the input string, store a boolean mask of what constraints (if any) exist for that token. Here is a function that accomplishes this:
def get_valid_tokens(input_str: str) -> Tensor:
input_ids = tokenizer(input_str, return_tensors='pt').input_ids
logits = torch.zeros((*input_ids.shape, len(tokenizer)))
out = torch.ones((*input_ids.shape, len(tokenizer))).bool()
start_idx = 0
for i in range(0, input_ids.shape[1]):
if input_ids[0, i] == tokenizer.eos_token_id:
start_idx = i
break
constrained_inputs = input_ids[:,start_idx:]
constrained_logits = logits[:, start_idx:, :]
for k in range(constrained_inputs.shape[1]):
out_logits = logits_processor(
constrained_inputs[:,:k+1],
constrained_logits[:,k,:])
out[:,k + start_idx,:] = out_logits > -1
return out
We could then use this mask to adjust the logits generated by the teacher model.
It is probably too strong to set all invalid tokens to logit -inf, but subtracting a fixed amount based on the mask will help condition the student model to respect the schema.
Because constraints may be applied at inference time (and indeed, this is where it is more important that the generated text adheres to them), a more performant approach to this is to use task-specific distillation.
Task distillation
As with model distillation in general, the idea behind task distillation is to build a smaller model that approximates the behavior of a larger one.
In contrast to our previous example of distilling GPT-2 on generic text, however, we are going to pick a larger model (in this case, Google’s gemma-2-2b-it, a 2-billion parameter instruction-tuned LLM), and include a specific task instruction in the teacher model’s prompt to condition its outputs.
The relationship that this has to the constrained distillation described above is, we may hope that by including the schema and other instructions in the task description, the teacher model’s logits already take into account the schema constraints of the problem.
The setup is very similar to the distillation training done above. The main difference is that a bit of bookkeeping we need to do: we’re not interested in feeding the student model the prompt, so we need to cut that portion of the input string out before feeding it to the student. Here’s the setup of the teacher model:
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-2b-it")
teacher = AutoModelForCausalLM.from_pretrained(
"google/gemma-2-2b-it",
torch_dtype=torch.bfloat16).to(device)
I’ve chosen the following prompt:
prompt = f"""Identify the parts of speech (POS) for each word
in the following sentence, and return the result as JSON according
to this JSON schema:
Schema: {AnnotatedSentence.model_json_schema()}
Sentence:"""
Since the prompt will be appended to the beginning of every input, I can track the prompt shape and just slice that portion of the input string out before feeding it to the student:
prompt_shape = tokenizer(prompt, return_tensors='pt').input_ids.shape[1]
# 151 tokens
The other subtlety is that we are only interested in training the student’s outputs given an input string, i.e. we do not care about the student learning the teacher’s probabilities for any non-JSON text.
This results in a few changes to the preprocess function we defined earlier:
def preprocess(data):
# input text is just the input string (including the prompt)
input_txt = tokenizer(
data["input_txt"],
truncation=True,
max_length=512)
# full text includes the prompt, sentence, and JSON
full_txt = tokenizer(
data["full_txt"],
truncation=True,
max_length=512)
# Huggingface uses the convention that labels = -100 are
# ignored by the loss function
labels = [
-100 for _ in input_txt.input_ids
] + full_txt.input_ids[len(input_txt.input_ids):]
# manual padding - because we are using a label mask,
# as well as to ensure right padding rather
# than left padding (as used by some tokenizers)
input_ids = full_txt.input_ids + [
tokenizer.pad_token_id
for _ in range(len(full_txt.input_ids), 512)]
attn_mask = full_txt.attention_mask + [
0 for _ in range(len(full_txt.input_ids), 512)]
labels = labels + [-100 for _ in range(len(labels), 512)]
return {
"input_ids": full_txt.input_ids,
"attention_mask": full_txt.attention_mask,
"labels": labels,
}
tokenized_dataset = data.map(preprocess)
Note that rather than using the built-in padding of the tokenizer, I am manually padding each sequence. This ensures that the padding is always on the right (some tokenizers, like Gemma’s, do left padding instead), which we will need in order to slice out the prompt text.
The student model I’m using is the same as before:
cfg = GPT2Config(
n_embd=192,
n_layer=12,
n_head=12,
)
student = GPT2LMHeadModel(cfg)
# note that we're using Gemma's tokenizer, not GPT's
student.resize_token_embeddings(len(tokenizer))
The loss function is once again just nn.KLDivLoss.
However, in contrast to our earlier DistillationTrainer, this time around we need to modify the loss calculation:
# Distillation loss: Logit matching
def compute_loss(teacher_outputs, student_outputs):
# Use KL-divergence between teacher and student logits
teacher_logits = teacher_outputs
student_logits = student_outputs
loss_fn = nn.KLDivLoss(reduction="batchmean")
return loss_fn(
student_logits.log_softmax(dim=-1),
teacher_logits.softmax(dim=-1)
)
class DistillationTrainer(Trainer):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
def compute_loss(
self,
model,
inputs,
return_outputs=False,
num_items_in_batch = None):
inputs = {k: v.to(self.args.device)
for k, v in inputs.items()}
teacher_input_ids = inputs["input_ids"]
teacher_attn_mask = inputs["attention_mask"]
# note that we slice the logits based on prompt length
student_input_ids = inputs["input_ids"][:,prompt_shape:]
student_attn_mask = inputs["attention_mask"][:,prompt_shape:]
label_mask = (inputs["labels"] != -100)[:,prompt_shape:]
# note that we slice the logits based on prompt length
with torch.no_grad():
teacher_outputs = teacher(
input_ids=teacher_input_ids,
attention_mask=teacher_attn_mask
).logits[:, prompt_shape:, :]
student_outputs = model(
input_ids=student_input_ids,
attention_mask=student_attn_mask).logits
loss = compute_loss(
teacher_outputs[label_mask],
student_outputs[label_mask])
return (loss, student_outputs) if return_outputs else loss
The rest of the training logic is the same as before. This time, however, when we generate sentences, we get outputs that appear to adhere somewhat better to our task than before:
student_generator = pipeline("text-generation",
tokenizer=tokenizer,
model=student,
device=device)
student_generator('It was the best of times<eos>{"tokens":',
max_length=25,
truncation=True,
num_return_sequences=5,
do_sample=True, temperature=1)
# returns (input snipped):
# [{"text":"They","pos":"Noun"},{"text":"PUNCT"},
# [{"text":"But",","pos":"VERB"}, {"text":"or'},
# [{"text":"Noun")","pos":"N"},{"text":"CC'},
# [\n\n```type\':\'string\'s a best.s me,'},
# [{"text":"PRON"},{"text":"in","pos":"ADJ'}]
This is still not great per say, but it is a significant improvement over the previous outputs of the model (which generally failed to resemble JSON at all, let alone adhere to our schema).
For our final model, we may fine-tune our distilled model on the actual task, and then at inference time, apply the JSONLogitsProcessor constructed earlier.
You might reasonably ask, why not simply train the model directly on the actual task data (the inputs and outputs)—why bother with the whole task distillation exercise?
The answer is twofold: first, task distillation can be thought of as a method of weight initialization for the student model: the teacher model, having been trained on a wider dataset, imparts that knowledge (via its logits) onto the student.
The distribution the student might learn when trained with a random initialization may be suited for the task at hand, but might not generalize well outside the training set.
(This can be thought of as an example of the lottery ticket hypothesis: we are trying to force the student network to approximate the teacher’s ‘winning ticket’.)
In any event, here’s the result after 20 epochs of fine tuning, again with the prompt “It was the best of times”:
{"tokens":[{"text":"You","pos":"PRON"},{"text":"was","pos":"AUX"},
{"text":"the","pos":"DET"},
{"tokens":[{"text":"It","pos":"PRON"},{"text":"is","pos":"AUX"},
{"text":"the","pos":"DET"},
{"tokens":[{"text":"That","pos":"PRON"},{"text":"is","pos":"AUX"},
{"text":"the","pos":"DET"}
{"tokens":[{"text":"I","pos":"PRON"},{"text":"is","pos":"AUX"},
{"text":"the","pos":"DET"},
Even though the results are incorrect, the model exhibits very strong adherence to the JSON schema. Applying the JSONLogitsProcessor does not particularly improve the result:
{"tokens":[{"text":"I","pos":"PRON"},{"text":"will","pos":"AUX"},
{"text":"the","pos":"DET"}
The errors the model makes are now not “grammatical” (in the sense of disobeying our schema), but “semantic” (in the sense of being incorrect responses for the task). This is an improvement from where we started! At this point, we may hypothesis that at 54 million parameters (a measly 2.7% the size of Gemma-2-2b), our model is simply not large enough to learn anything more about the task than what format its output should be in, and the parts of speech of the most common English words.
In fact the model’s knowledge of parts of speech is easily tested by running a few phrases through and seeing which part of speech is predicted:
Prompt: To be or not to be<eos>{"tokens":[{"text":"To","pos":"
Completion: PART"},{"text":"be","pos":"AUX"},
Prompt: He was there<eos>{"tokens":[{"text":"He","pos":"
Completion: PRON"},{"text":"you","pos":"PRON"},
Propmt: He was there<eos>{"tokens":[{"text":"He","pos":"PRON"},
{"text":"was","pos":"
Completion: AUX"},{"text":"?","pos":"PUNCT"}
The model apparently is quite adept at correctly predicting the part of speech of a given word (at least for common English words), but quite a bit worse at recalling which words appeared in the prompt sentence.
For completeness, it is also worth mentioning that the training set used in this blog is exceptionally small—just the “dev” UD English GUM corpus—and so it is also possible that additional training data would improve model performance. Nevertheless, the methods shown here are easily extensible to arbitrary tasks and datasets. In general, any task that can be phrased as a text completion is, at least theoretically, solveable by an LLM of sufficient size and sufficient training corpus (although “sufficient” is doing a lot of work in that claim). The methodology shown here provides a way to distill such models to a reasonable size and also ensure their outputs are consumable by downstream systems. This is in some sense a riposte to the “model-as-a-service” business model of OpenAI or Anthropic, and it will be interesting to see how LLM usage evolves as the market matures: will the future be increasingly large and expensive “foundational” models, capable of many tasks and charging a fixed fee per token? Or will it be much smaller, single-purpose models, perhaps requiring some setup cost, but orders of magnitude cheaper to deploy and run inference on?